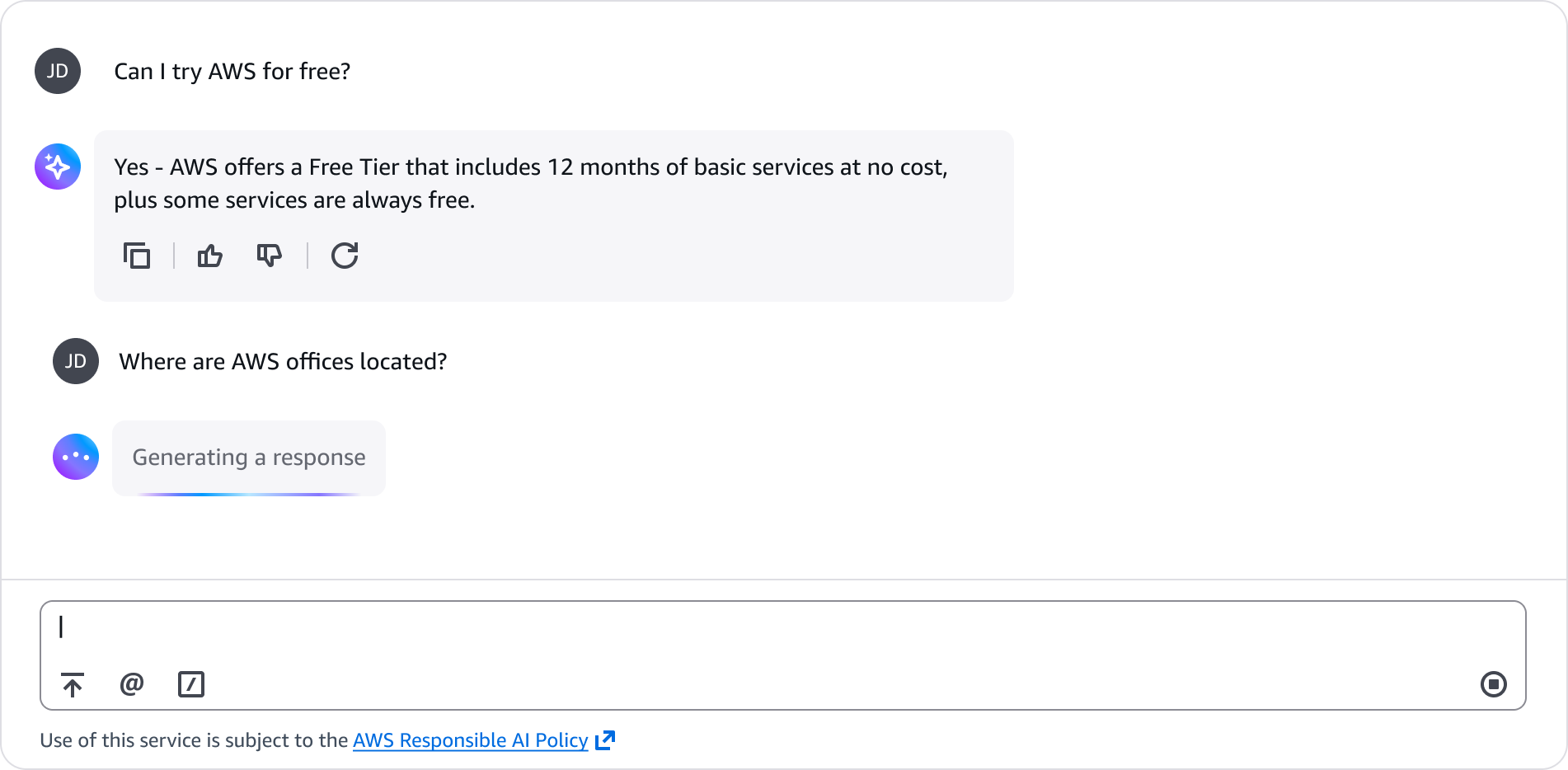
Response regeneration
Enables users to generate an alternative response in generative AI chat.
Enables users to generate an alternative response in generative AI chat.
A user can request a new version of a model's response, which generates an alternate response to replace the original one. This approach maintains the conversation's prior context while allowing users to explore alternative responses to their questions. The same process applies whether the original response was completed or interrupted by the user through a stop action.
During regeneration, the model performs a new sampling process to generate an alternative response. While using the same prompt and conversation context, the model can produce varied outputs due to the probabilistic nature of language model generation. This is similar to getting different arrangements each time you shuffle a deck of cards.
Regeneration happens when a user selects an explicit regenerate icon button. The model then replays the exact same input to generate a new response. Alternatively, typing a phrase like “try again” or “regenerate that” is a new, natural language prompt that the system interprets contextually as a new request.
Context builds a shared understanding between user and system throughout their conversation. When a user regenerates a response, it changes the conversation's path from that point, like traveling back in time to take a different direction forward. To maintain consistent context, the system removes all messages that came after the regenerated response. This ensures the conversation can continue naturally along its new path without conflicting with messages from the previous direction.
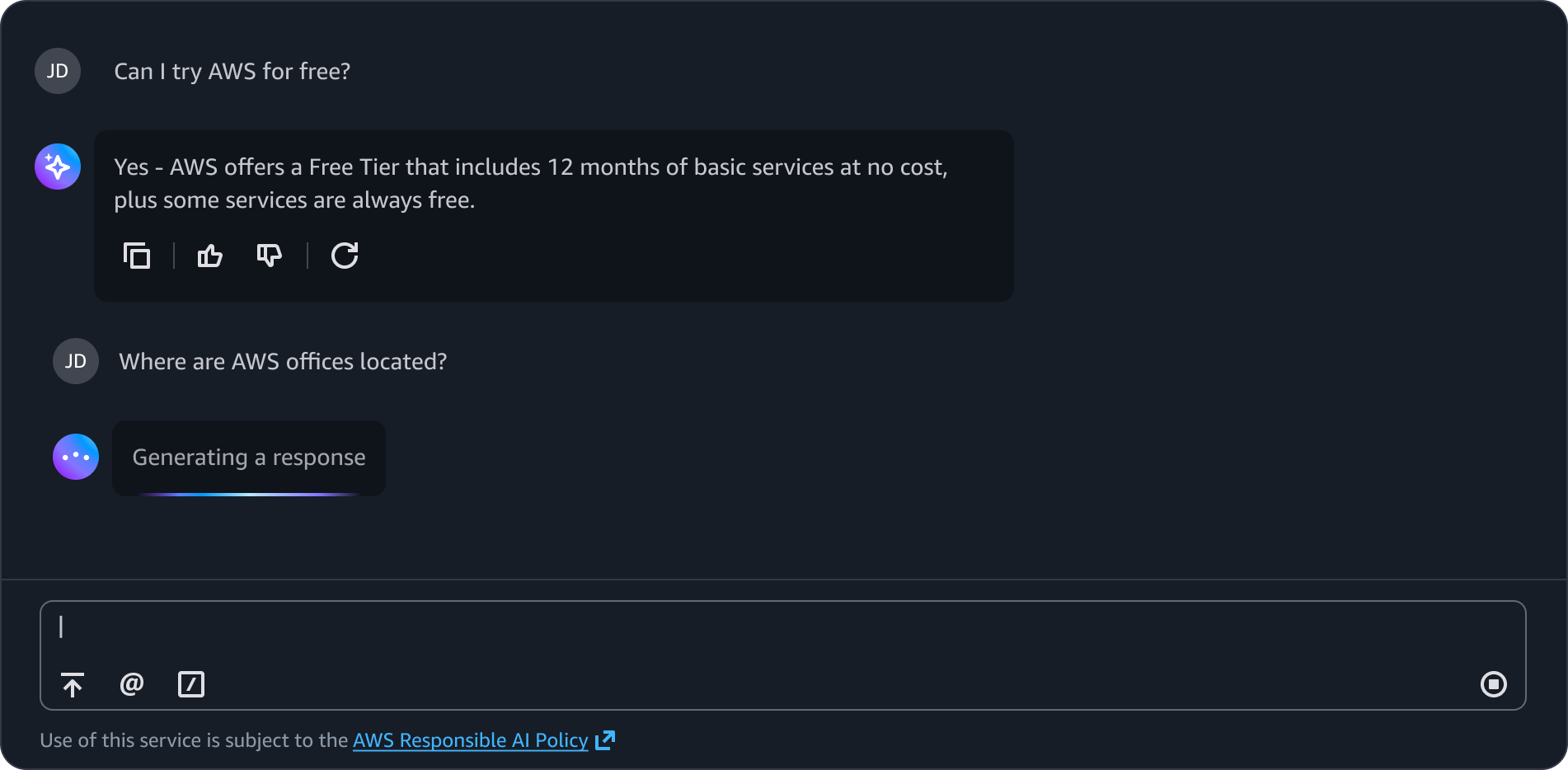
The user's original question using the chat bubble outgoing message with an avatar to indicate it's a sent message.
The system’s response is displayed using the chat bubble incoming message and generative AI avatar to indicate it's a received message.
An icon button within the button group with a refresh icon that allows users to request an alternative response to the same prompt. Appears consistently below each eligible system response.
After a user has sent a prompt, the send button changes to a stop button which enables users to interrupt the generation or processing of a response.
Users can regenerate a completed response to see alternative versions of the same response. The action reuses the original user prompt and context so the conversation stays coherent while exploring new outputs.
Users can stop generation as soon as they notice an unwanted response direction. This prevents the model from consuming additional tokens generating an unwanted response. The regenerate option becomes immediately available, letting users quickly pivot to better alternatives. For example, if a user sees the response taking an overly technical approach, they can stop the generation and use regenerate to get a different response to their original prompt without changing anything.
Use sentence case, but continue to capitalize proper nouns and brand names correctly in context.
Use end punctuation, except in headers and buttons. Don’t use exclamation points.
Use present-tense verbs and active voice.
Don't use please, thank you, ellipsis (...), ampersand (&), e.g., i.e., or etc. in writing.
Avoid directional language.
For example: use previous not above, use following not below.
Use device-independent language.
For example: use choose or select not click.
Follow the guidelines on alternative text and Accessible Rich Internet Applications (ARIA) regions for each component.
Make sure to define ARIA labels aligned with the language context of your application.
Don't add unnecessary markup for roles and landmarks. Follow the guidelines for each component.
Provide keyboard functionality to all available content in a logical and predictable order. The flow of information should make sense.